Transformer Architecture
Table of Contents
See RNN and Transformers (MIT 6.S191 2022) for link to video lecture.
Transformer architecture
- Identify parts to attend to
- and Extract features with high attention
Attention has been used in:
- AlphaFold2: Uses Self-Attention
- BERT, GPT-3
- Vision Transformers in Computer Vision
1. Idenitfying parts to attend to is similar to Search problem
- Enter a Query (\(Q\)) for search
- Extract key information \(K_i\) for each search result
- Compute how similar is the key to the query: Attention Mask
- Extract required information from the search i.e. Value \(V\)

Figure 1: Attention as Search
2. Self-Attention in Sequence Modelling
Goal: Identify and attend to most important features in input
We want to elimintate recurrence because that what gave rise to the limitations. So, we need to encode position information

Figure 2: Position-Aware Encoding (@ 0:48:32)
- Extract, query, key, value for search
- Multiply the positional encoding with three matrices to get query, key and value encoding for each word
- Compute attention weighting (A matix of post-softmax attention scores)
Compute pairwise similarity between each query and key => Dot Product (0:51:01)
Attention Score = \(\frac {Q . K^T} {scaling}\)
- Apply softmax to the attention score to get value in \([0, 1]\)
- Extract features with high attention: Multiply attention weighting with Value.
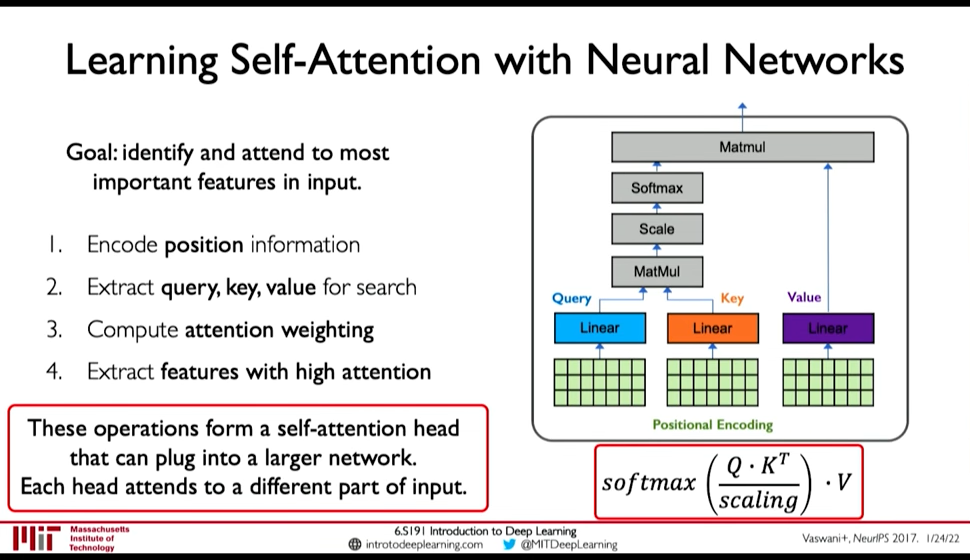
Figure 3: Self-Attention Head
3. Types of LLM Architecture
Three distinct configurations using the same attention mechanism, optimized for different tasks:
3.1. Encoder only
- Purpose: Understanding and representation
- Mechanism:
- Bidirectional self-attention (each token sees all other tokens). It is called bidirection but direction is in logical sense. Every token attends to every other token. In contrast, in decoder only architecture the attention is masked i.e. \(Q K^T\) result is set to \(-\infty\) for \((i, j)\) pair where \(j > i\), and thus enforcing unidirectional attention.
- Processes entire input simultaneously
- Outputs rich numerical embeddings
- Use cases:
- Sentiment analysis
- Named entity recognition
- Text classification
- Any task requiring whole-sentence understanding
- Example: BERT
3.2. Decoder only
- Purpose: Text generation
- Mechanism:
- Masked (causal) self-attention (tokens only see previous tokens)
- Auto-regressive: predicts next token based on prior context
- Cannot look ahead (prevents "cheating")
- Use cases:
- Chatbots and conversational AI
- Creative writing
- Code generation
- Any generative task
- Example models: GPT-4, Llama, Claude
3.3. Encoder-Decoder
- Purpose: Transforming one sequence into another
- Mechanism:
- Encoder: Processes full input bidirectionally and creates a context map
Cross-attention: Bridge connecting encoder output to decoder
Query is from decoder, Key and Value is from encoder
- Decoder: Generates output token-by-token using:
- Self-attention (what it's already written)
- Cross-attention (encoder's context map)
- Use cases:
- Machine translation (different languages)
- Abstractive summarization (long → short)
- Image captioning (vision encoder → text decoder)
- Generative QA (document-specific answers)
- Example models: T5, BART, original Transformer (2017)
3.4. Comparision
The benefit of encoder-decoder model is that it is parameter efficient at small scale. But this requires paired training data. Its used in DeepL, Google Translate core. Other properties are:
- Highest accuracy for pure translation
- Lower latency per word
- More cost-effective at massive request scale
- Specialized pipeline (Language A → Language B)
Whereas decoder only network:
- learns from unsupervised web data
- at big scale (70B+) matches or exceeds quality of encoder-decoder network
- Single model handles all tasks
- Better tooling/optimization (vLLM, TensorRT-LLM)
- Natural conversational flow