Reinforcement Learning
Table of Contents
- 1. Resources
- 2. Papers
- 3. Concepts
- 3.1. True Gradient Descent
- 3.2. Actions are Infinite
- 3.3. RL Without Rewards
- 3.4. Action Chunking
- 3.5. Horizon Reduction is needed to scale RL
- 3.6. Diffusion/Flow policy
- 3.7. Early Stopping of Episodes improves RL
- 3.8. Agents are World Model
- 3.9. Neuroscience meets RL - AXIOM
- 3.10. Encoder can improve RL performance without Algorithmic changes
- 3.11. Divide and Conquer Reinforcement Learning
- 3.12. Synergistic Action Representation
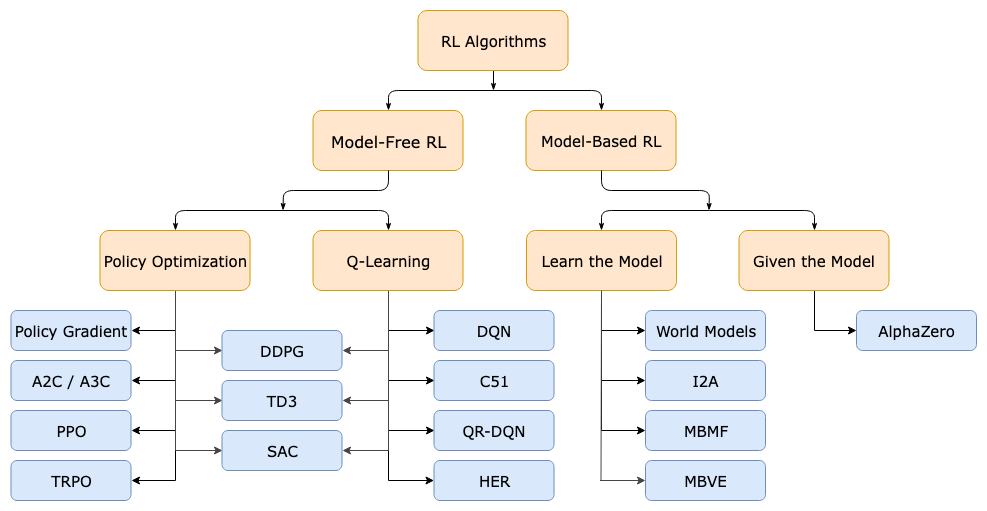
Figure 1: A Taxonomy of RL Algorithms [from spinningup.openai.com]
1. Resources
Lectures:
- MIT 6.S191: Reinforcement Learning [YT] (Good overview for begineers)
- CS 285: Deep Reinforcement Learning - Sergey Levine: https://rail.eecs.berkeley.edu/deeprlcourse/
- CS 234: Reinforcement Learning - Emma Brunskill: https://www.youtube.com/playlist?list=PLoROMvodv4rOSOPzutgyCTapiGlY2Nd8u
Books:
- Reinforcement Learning: An Introduction by Sutton and Barto is still the intro book that estabilishes base for learning RL.
- Distributional Reinforcement Learning by Bellemare, Dabney & Rowland is a specialied book looking at RL in a new perspective that advances the theory of RL
- Deep Reinforcement Learning Hands-On by Maxim Lapan (2024) is practical and implementation focused approach
- Multi-Agent Reinforcement Learning: Foundations and Modern Approaches by Albrecht, Christianos & Schafer (2024) gives comprehensive intro to MARL
Software:
- Stable Baseline - Collection of RL Algorithms
Articles:
- A guide for learning Deep RL by OpenAI: spinningup.openai.com
- Debugging RL Algorithms andyljones.com talks about:
- Probe Environments
- Probe Agents
- Logs execessively
- Use really large batch size
- Rescale your rewards
- A collection of psuedocode of RL Algorithms with notes on which to use when : datadriveninvestor.com
- A collection of RL algorithms and their comparision: jonathan-hui.medium.com
- List of Thesis in RL: reddit.com
- A (Long) Peek into Reinforcement Learning : lilianweng.github.io
Podcasts:
- TalkRL: podcasts.apple.com
Implementation details:
- The 37 Implementation Details of Proximal Policy Optimization: https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/
- Implementation Matters in Deep RL: A Case Study on PPO and TRPO: https://openreview.net/forum?id=r1etN1rtPB
- What Matters for On-Policy Deep Actor-Critic Methods? A Large-Scale Study: https://openreview.net/forum?id=nIAxjsniDzg
See also:
2. Papers
Notes:
Minimal notes:
- Goal-Conditioned Supervised Learning
- Reward Conditioned Policies
- The Surprising Effectiveness of PPO in Cooperative Multi-Agent Games
- Encoder can improve RL performance without Algorithmic changes - Model Free Atari
- Agents are World Model
- Rainbow DQN
- Divide and Conquer Reinforcement Learning
- Synergistic Action Representation
PDFs:
- Intention Conditioned Value Function (ICVF)
- Learning Multi-agent Implicit Communication Through Actions: A Case Study in Contract Bridge, a Collaborative Imperfect-Information Game. [pdf]
Learning Decision Trees With RL [pdf]
Trains a RNN network using RL, to decide which feature to split the decision tree next. Performs better than greedy strategy. Because greedy strategies look on immediate infromation gain, where RL can be trained for longterm payoff.
- Iterated Q Network
- Solving Offline Reinforcement Learning with Decision Tree Regression
3. Concepts
3.1. True Gradient Descent
Is DQN True Gradient Descent? No. They are approximations to it. CS234 - Lecture 6 (t=3253)
Because it is not a derivative of a loss function.
- GTD (Gradient Temporal Difference) are true gradient descent
- The first section of chapter on Function Approximation (Sutton & Barto) has few points on this.
3.2. Actions are Infinite
From Assumptions of Decision Making Models in AGI:
It is unreasonable to assume that at any state, all possible actions are listed.
Actions in small scale may be discrete or a finite collection of distributions, but at the level where planning happens set of all possible actions is infinite.
Such actions can in principle to thought to be recursively composed of a set of basic operations/actions. But the decision making happens not at those basic actions but at level of composed actions.
- It is a task in itself to know what actions can be taken and what actions should we evaluate.
Thus decision making involves composing short timestep actions to get longer term action over which planning can be done.
i.e. decision making is often not about selection but selective composition. [Page 2]
So, one thing to explore would be Hierarchical Reinforcement Learning.
3.3. RL Without Rewards
What does this even mean?
Is it even RL if there are no rewards. So, this must be limited to improving performance in downstream tasks that do indeed have rewards?
What is the utility?
- helps when the reward is sparse
- skills developed without reward can act as primitive for hierarchical RL
Work done so far:
- ICVF
- Diversity is all you need.
3.4. Action Chunking
Action chunking works good in imitation learning. So, why not apply it to RL. [twitter]
\begin{align*} Q(s_t, a_{t:t+h}) = \sum_{t'=t}^{t+h-1} \gamma^{t'-t} r_{t'} + \gamma^h Q(s_{t+h}, a_{t+h:t+2h}) \end{align*}This is n-step returns but the use of n-step Q-value fixes the problem of being biased.
We also need to make the policy match the offline data i.e. impose behavior constraint.
3.5. Horizon Reduction is needed to scale RL
Paper: Horizon Reduction Makes RL Scalable [twitter][arXiv]
If we scale the data and compute for offline RL, the performance doesn't improve except for when you do Horizon reduction.
Using n-step returns improved "asymptotic" performance, and full hierarchical RL scaled even better.
Why does simple TD learning not scale? Because prediction targets are biased and biases accumulate over the horizon. And this bias is not easily mitigated by scaling data and compute.

3.6. Diffusion/Flow policy
Handling complex behaviour distribution requires more expressive policy class like diffusion/flow policies. [twitter]
3.7. Early Stopping of Episodes improves RL
Method: LEAST (Learn to Stop)
Paper: "The Courage to Stop: Overcoming Sunk Cost Fallacy in Deep RL" [twitter] [arXiv]
RL agents need to finish episodes even if they start bad. This wastes time, fills replay buffer low quality data and thus slows learning.
To decide whether to stop or not it builds adaptive thresholds using:
- Median Q-values (for episode quality)
- Median gradient magnitudes (for learning potential)
Dual-criteria stopping outperforms simpler rules based on Q-values alone
This method can be used in conjunction with other methods (TD3, SAC, REDQ, …) and improves them.
Side benefit:
- Improves plasticity of network (i.e. network learns for longer) thus helping on long horizon tasks
3.8. Agents are World Model
Paper: General agents need world model [twitter][arXiv]
Is world model necessary for human level AI or is there a model-free shortcut? It turns out that agents themselves have world model inside them.
We prove that any agent capable of generalizing to a broad range of simple goal-directed tasks must have learned a predictive model capable of simulating its environment. And this model can always be recovered from the agent.
It is possible to extract an approximation to the environemnt transition function from any goal conditioned policy.
3.9. Neuroscience meets RL - AXIOM
Paper: AXIOM: Learning to Play Games in Minutes with Expanding Object-Centric Models [arXiv]
From verses.ai:
- lab grown brain cells "Dishbrain" learned to play Pong [arXiv] using Free Energy Principle and Active Inference
- AXIOM takes inspiration from that appraoch
This alternative path to applying neuroscience-based methodologies and biologically plausible techniques to tackle Atari began in 2022, when Professor Friston and our colleagues from Cortical Labs demonstrated how lab-grown brain cells, called “Dishbrain”, learned to play Pong demonstrating that neurons apply the Free Energy Principle and operate using Active Inference. A 2023 paper published in Nature confirmed the quantitative predictions of the Free Energy Principle using in vitro networks of rat cortical neurons that perform causal inference. In early 2024 we applied these same underlying Active Inference mechanics demonstrated with Dishbrain to playing Pong purely in software.
Resources:
- Papers by VERSES:
- Biological Neurons Compete with Deep Reinforcement Learning in Sample Efficiency in a Simulated Gameworld [arXiv]
3.10. Encoder can improve RL performance without Algorithmic changes
Paper: Hadamax Encoding: Elevating Performance in Model-Free Atari. [twitter][arXiv]
By just changing the encoder improved the performance in model free atari problem. E.g. C51 showed 60% improvement.
The most important design choices for encoder were:
- Convolutional Hadamard Representations,
- Max-pooling instead of convolutional down-sampling,
- Gaussian Error Linear Unit activations.
This shows sometimes a lot is to be gained by without changing the algorithm but just by changing the architecture.
3.11. Divide and Conquer Reinforcement Learning
[pdf]
Partition the initial state space \(S_0\) into clusters (called contexts) using clustering algorithm (k-means clustering). Then train a different policy (a local policy) for each cluster. This makes the learning problem easier when the initial state space is diverse and wide. When the initial state space is wide, the policy gradient updates have high variance and this affects learning.
Now, to create a global policy (called central policy in the paper) out of the learned policy for each cluster, minimize the KL divergence between the local policy and central policy for the visited trajectories. This step is called supervised distillation, and is done after some steps of local policy updates. After distillation the local policies are initialized to be global policy, and again their training repeats in their context for some steps until next distillation.
All this so far describes the "Unconstrained Divide and Conquer" algorithm. But it is better if the local policies share information with each other during learning. This is done through a divergence constraint (eqn 3) on the local policy that encourages each local policy to be close to other local policies in its own context and to mimic other local policies in their contexts.
This is the final algorithm, called "DnC" in the paper.
Notes:
[Appendix C] Number of paritions (i.e. contexts) is a trade-off between information sharing and easier learning of local policies.
When there are many contexts, there is less information sharing between the local policies but learning for each small set of initial states becomes easier.
Algorithm:
R ← Distillation Period function DNC() Sample initial states \(s_0\) from the task Produce contexts \(\omega_1\), \(\omega_2\), . . . \(\omega_n\) by clustering initial states \(s_0\) Randomly initialize central policy \(\pi_c\) for t = 1, 2 … until convergence Set \(\pi_i\) = \(\pi_c\) for all i = 1 … n for R iterations do Collect trajectories \(T_i\) in context \(\omega_i\) using policy \(\pi_i\) for all i = 1 … n for all local policies \(\pi_i\) Take gradient step in surrogate loss \(\mathcal{L}\) wrt \(\pi_i\) Minimize \(\mathcal{L}_{center}\) w.r.t. \(\pi_c\) using previously sampled states \((T_i)^n_{i=1}\) return \(\pi_c\)
3.12. Synergistic Action Representation
Generalization of Physiological Agility and Dexterity via Synergistic Action Representation [Blog][pdf][arXiv][Tutorial Code]
Process:
- Play Phase:
- Train a NN on a simpler task using RL for some timesteps (e.g. 1.5M)
- Let the model play for some timesteps (e.g. 20k) and collect actions that give good rewards (say, rewards above 80% percentile)
- Compute SAR:
- Do n-component PCA on the collected actions
- Do ICA on the PCA results
- Do MinMaxScaler
Train a NN on desired task with a modified action space of original actionspace + N component action space of SAR

Benefits:
Sample efficiency is improved

- The trained method generalizes better - in zero shot as well as finetuning
- SAR learned in one task can be used on other different tasks
- The motions obtained were more natural
Backlinks
- Assumptions of Decision Making Models in AGI
- Epistemic Uncertainty
- Free Energy Principle
- Genetic Algorithm
- Hierarchical Reinforcement Learning
- Hippocampal Replay & Planning
- Model Based Reinforcement Learning
- Papers
- Procgen Benchmark
- Recurrent World Models
- Reinforcement Learning
- RL can be used to train Non-Differentiable Models
- Sergey Levine
- Supervised Learning for RL